Real-World AI, Not-So-Real Foundations: How Synthetic Data Shapes the World’s Leading Models
Meet Margaret Lewis, a 56-year-old woman who recently noticed a faint tightness in her chest and shortness of breath while climbing the stairs. Her temperature was 36.9°C, blood pressure 138/82 mm Hg, and oxygen saturation 95% on room air. A gentle wheeze echoed at the base of her lungs, and a synthetic chest X-ray revealed mild hyperinflation but no sign of infection. Her lab results were largely normal except for a mildly elevated C-reactive protein. Taken together, Margaret’s symptoms indicated the earliest signs of chronic obstructive airway disease — thankfully mild and manageable with a simple inhaler and some lifestyle changes.
At first glance, Margaret’s case appears entirely normal, a far from uncommon diagnosis. Her file is one of thousands in a dataset used to train AI models. But Margaret never had that condition, and none of her vitals were ever measured. In fact, Margaret doesn’t even exist — her entire patient file was created by ChatGPT!

Above: Image courtesy of Adobe Stock.
Data is everywhere in our lives; it’s how we make connections, find correlations and measure success and failure. Data is how we learn and improve. And for a long time, we have largely assumed that data for building real-world models must be measured from the real world. This is no longer the case.
Synthetic data is artificial data generated by statistical algorithms, often involving generative AI. These data do not use real-world measurements, but instead are designed to resemble patterns found in real world data. Margaret may not be real, but her symptoms and medical condition mirror trends observed in real patient files.
Benefits of Synthetic Data
One reason why synthetic data is being used is that real-world data often come with privacy concerns. Patients may not want their health data shared with outside companies, and students may not want their grades shared publicly. The United States has privacy regulations like the Health Insurance Portability and Accountability Act (HIPAA) and Family Educational Rights and Privacy Act (FERPA) that protect sensitive records. The European Union goes even further with a broader set of privacy regulations: the General Data Protection Regulation (GDPR).
Synthetic data avoids these issues entirely. Because it doesn’t use real measurements, it can be shared and analyzed freely without violating privacy or ethical standards. Thus, synthetic data enables researchers to conduct the same research and analysis while protecting the privacy of individuals.
Another major challenge is data availability. While real-world data is abundant, it may be insufficient to train certain machine learning models. Synthetic data can provide useful edge cases that are not widely available in real datasets. Furthermore, gathering real-world data is often expensive and time consuming, whereas generating synthetic data is much more efficient.

Above: Schematic showing the applications of synthetic data in various industries. Image courtesy of Turing.
Drawbacks of Synthetic Data
At the same time, there are valid concerns about the use of synthetic data. While it’s designed to mimic real world measurements, accuracy remains a major concern. Research has shown that there tends to be an inverse relationship between privacy and accuracy, making it difficult to achieve both.
Some studies have found that training AI using AI-generated data leads to a phenomenon known as model collapse or unfairness feedback loops. In generative models, including large language models (LLMs), training AI using synthetic data can cause some variation to disappear, creating “irreversible defects” in those models. This shifting of data distributions allows the biases of AI models to be embedded and amplified. The impact especially harms minority groups which may be underrepresented in the original dataset. As a result, AI models trained using synthetic data may be less representative of real-world scenarios than they should be.
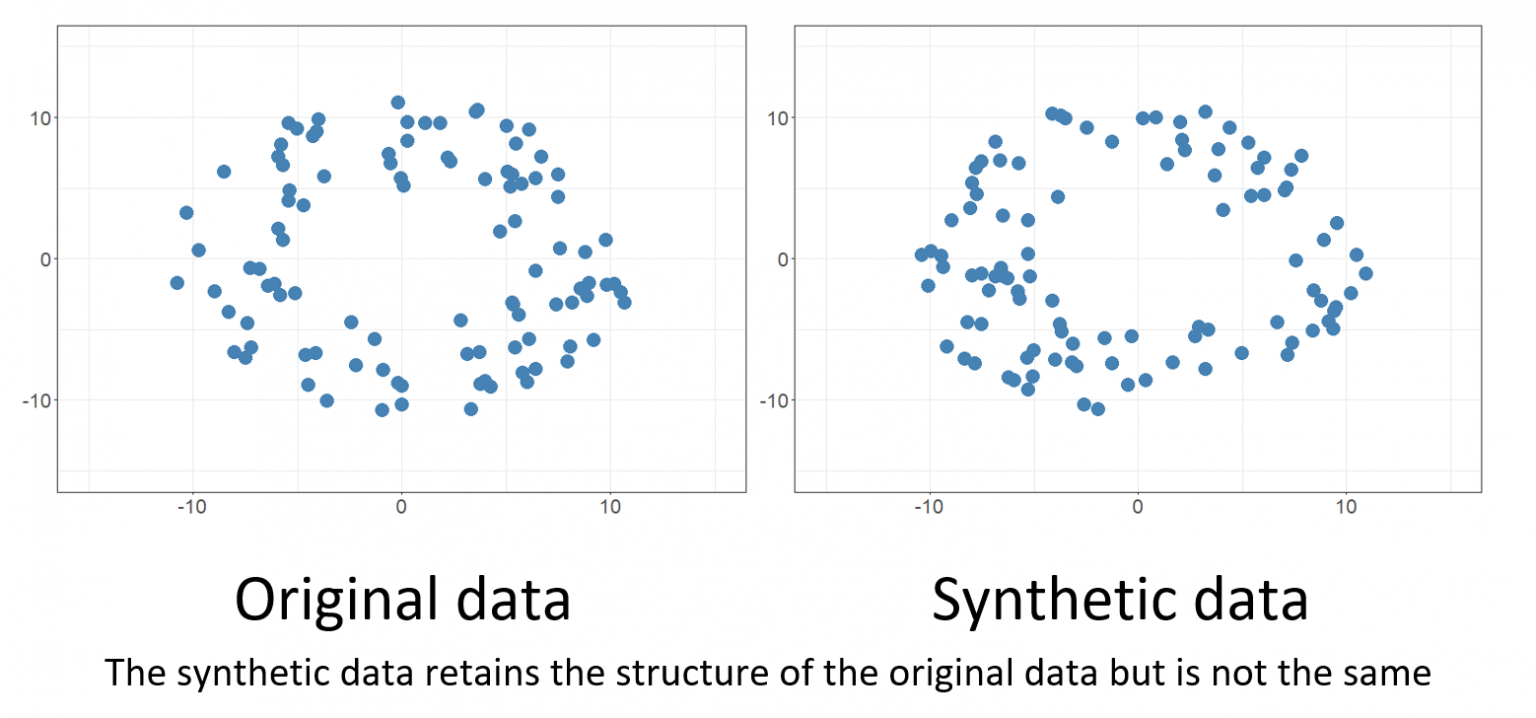
Above: Synthetic data has a similar structure that mimics the original data set, but the individual data points are different. Image courtesy of GOV.UK.
Potential Solutions: Balancing Privacy and Accuracy
The trade-off between privacy and accuracy in machine learning is an important discussion, and it’s clear that achieving one often comes at the expense of the other. Nevertheless, there are some solutions to preserve the usefulness of synthetic data while minimizing the bias and inaccuracy. Fairness pre-processing of synthetic data has been found to increase data fairness. For example, the DEbiasing CAusal Fairness (DECAF) algorithm is designed to find the optimal balance between accuracy and privacy. A recent study has shown that DECAF outperforms other algorithms in finding a balance, although other algorithms perform better when prioritizing either privacy or accuracy over the other.
Another study explored a different approach: algorithmic reparation. In this method, researchers use a different AI model to “repair” the bias of a synthetic dataset, promoting greater equity. This builds on the idea that machine learning models are inherently neutral and allows algorithms that show signs of bias to be corrected.
Synthetic data is a promising tool for training AI, especially in industries like healthcare where data privacy is essential. Nvidia’s purchase of synthetic data startup Gretel last March for nine figures demonstrates how important this area will be in the coming years. As the use of synthetic data grows, researchers can explore previously inaccessible areas, developing AI models to drive innovation and potentially save millions of lives.
